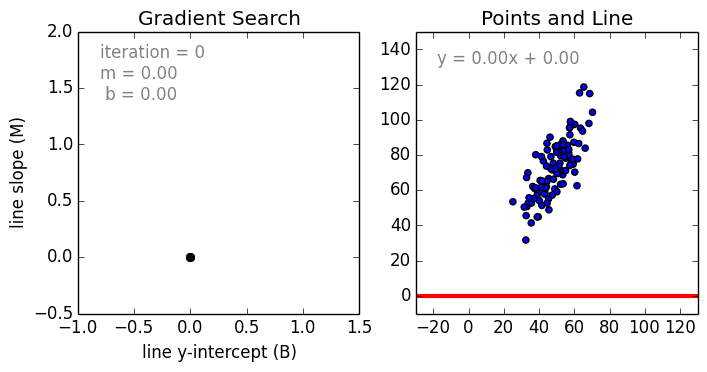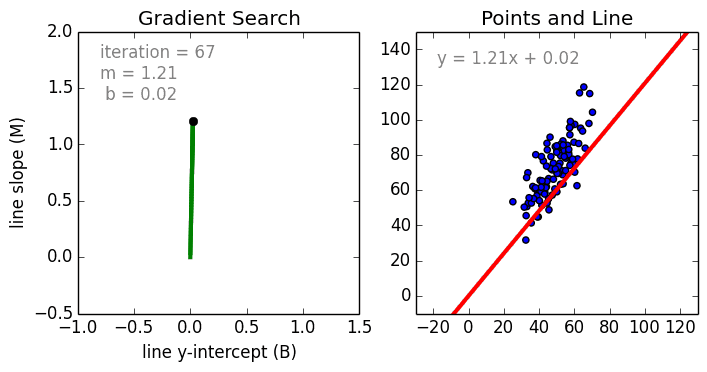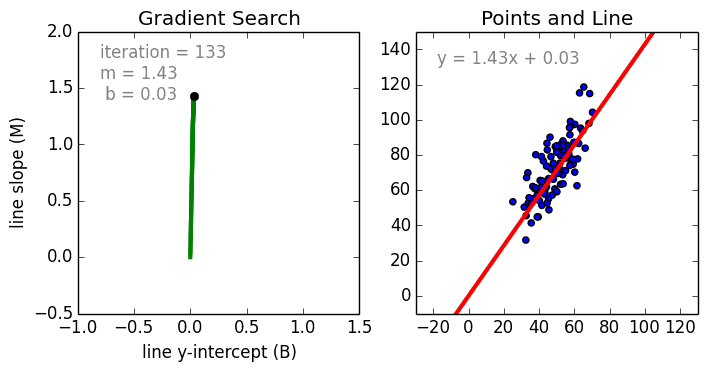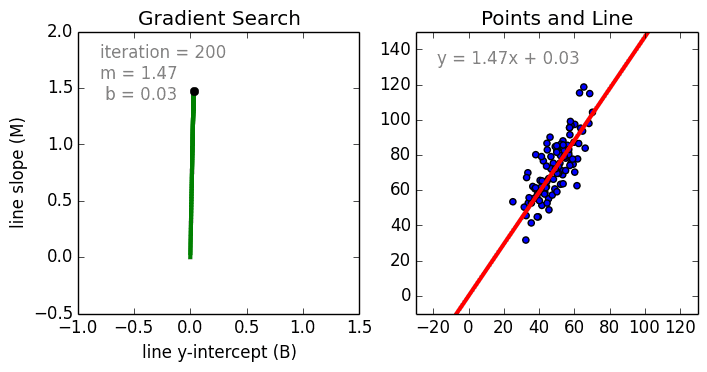
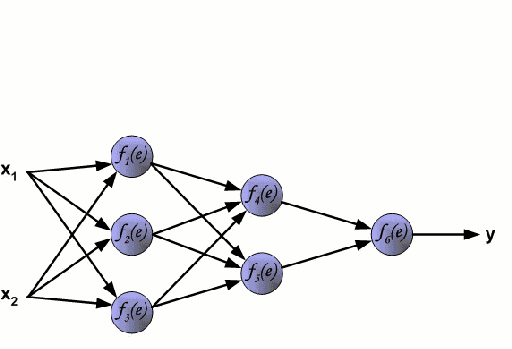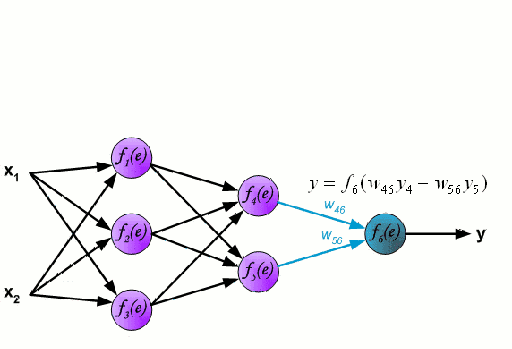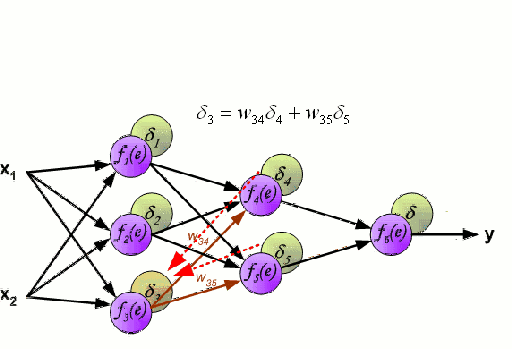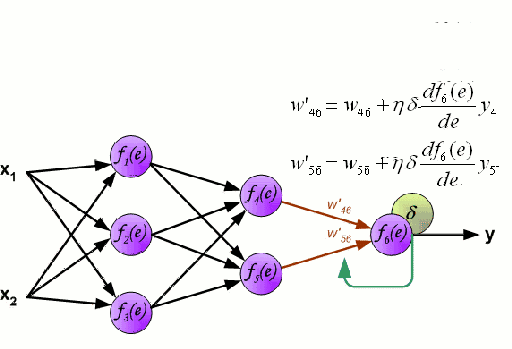
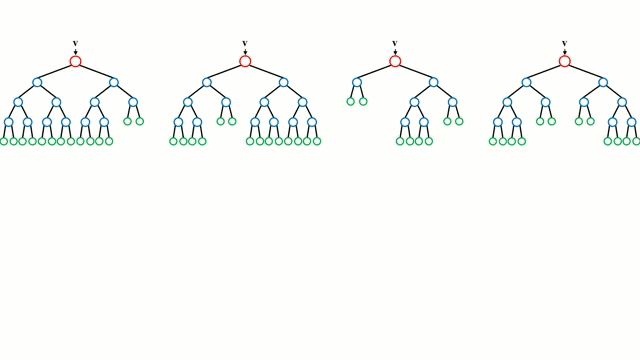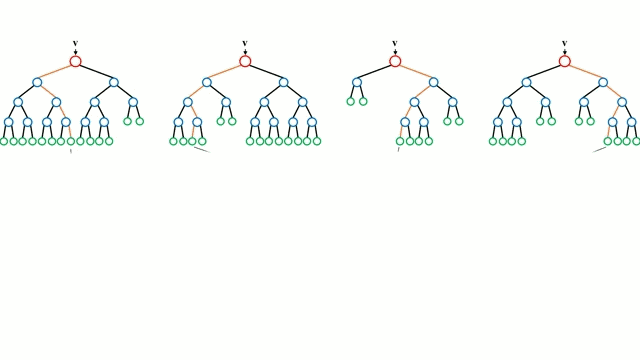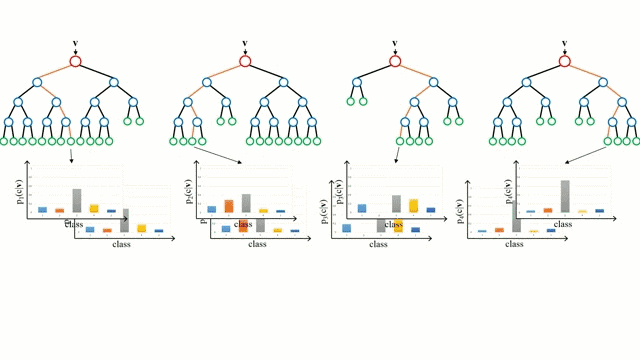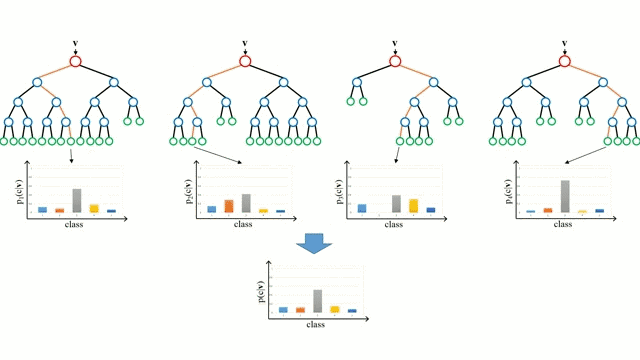
Any machine learning problem has more than one algorithm to solve. In the field of machine learning, "no free lunch" means that there is no algorithm that is good for all problems. The performance of machine learning algorithms is largely related to the structure and scale of the data. So the best way to judge the performance of the algorithm is to run the comparison on the data. But at the same time, we have a certain understanding of the advantages and disadvantages of the algorithm can help us find the algorithm we need. This article will introduce three regression algorithms and their advantages and disadvantages, which will provide us with a good help in understanding and selecting algorithms. Linear and polynomial regression In this simple model, the task of univariate linear regression is to establish a linear relationship between independent variables and dependent variables of a single input; while multivariate regression means to establish multiple independent input variables and output variables. Relationship. In addition, nonlinear polynomial regression performs a series of nonlinear combinations of input variables to establish a relationship with the output, but this requires some knowledge of the relationship between input and output. The training regression algorithm model generally uses the stochastic gradient descent method (SGD). advantage: Rapid modeling, effective for small data volumes and simple relationships; Linear regression models are easy to understand and facilitate decision analysis. Disadvantages: It is difficult to model nonlinear data or correlation between polynomial regressions; It is difficult to express highly complex data well. Neural Networks The neural network is connected by a series of nodes called neurons through the internal network. The characteristics of the data are passed to the network step by step through the input layer to form a linear combination of multiple features. Each feature will interact with the weights in the network. effect. The neuron then nonlinearly changes the linear combination, which makes the neural network model have complex nonlinear representation capabilities for multiple features. The neural network can have a multi-layered structure to enhance characterization of input data features. People generally use the stochastic gradient descent method and the back propagation method to train the neural network. Please refer to the above diagram. advantage: Multi-layered nonlinear structures can express very complex nonlinear relationships; The flexibility of the model makes us not need to care about the structure of the data; The more data, the better the network performance. Disadvantages: The model is too complicated to explain; The training process requires a lot of computational power and requires fine tuning of the hyperparameters; It relies heavily on the amount of data, but regular machine learning problems use smaller amounts of data. Returning to the tree and returning to the forest Let us start with the most basic concept. The decision tree is a model that traverses the branches of the tree and selects the next branch according to the decision of the node. Tree-awareness uses training data as data, splits according to the most appropriate features, and continuously circulates the training data to be classified into one category. In the process of building a tree, it is necessary to establish the separation on the purest child nodes, so as to keep the number of separations as small as possible in the case of separating features. Purity is a concept derived from information gains, which indicates how much information is needed for a sample that has never been met before it can be properly classified. It is actually defined by comparing the entropy or the amount of information required for classification. The random forest is a simple set of decision trees. The input vector is processed by multiple decision trees. Finally, the regression needs to average the output data, and for the classification, the voting mechanism is introduced to determine the classification result. advantage: It has a high degree of complexity and a high degree of nonlinearity and has a better effect than a polynomial fit; The model is easy to understand and clarify, and the decision boundaries in the training process are easy to practice and understand. Disadvantages: Because decision trees have a tendency to fit, the complete decision tree model contains many structures that are too complex and unnecessary. But this problem can be alleviated by expanding random forests or pruning; Larger random numbers perform well, but they introduce slow running and high memory consumption.
Freezer Condenser
1. Material: Bundy tube (steel tube coated with copper)
2. Structure: Bundy tubes welded with steel wines
3. Painting: Cathode electrophoretic painting(black)
4.
Can produce according to drawing or sample supplied by clients, also
can help the clients design and produce different condensers.
Freezer Condenser,Freezer Condenser Unit,Deep Freezer Condenser,Fridge Freezer Condenser FOSHAN SHUNDE JUNSHENG ELECTRICAL APPLIANCES CO.,LTD. , https://www.junshengcondenser.com