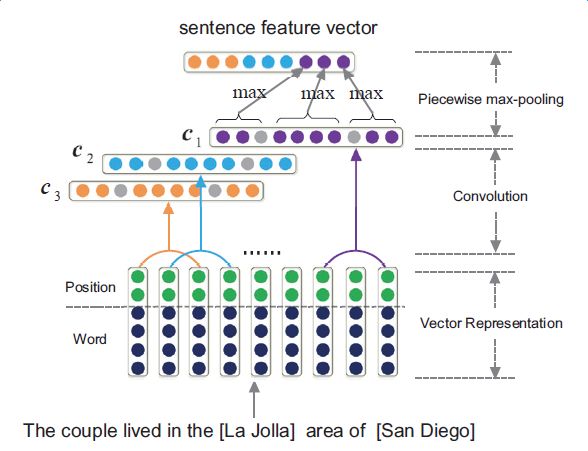
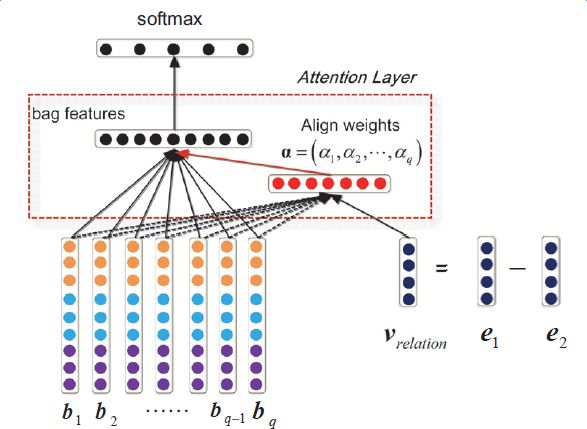
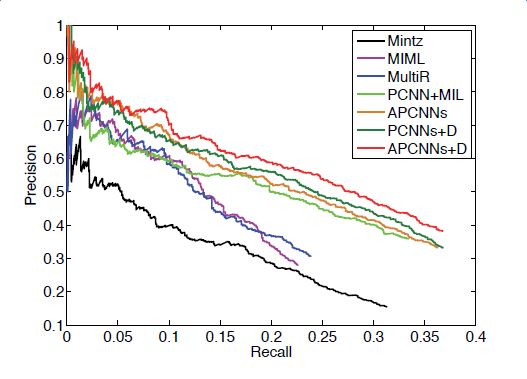
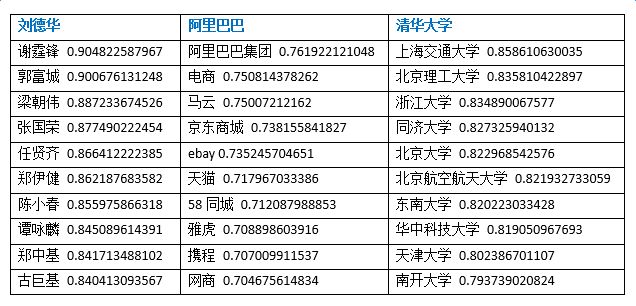
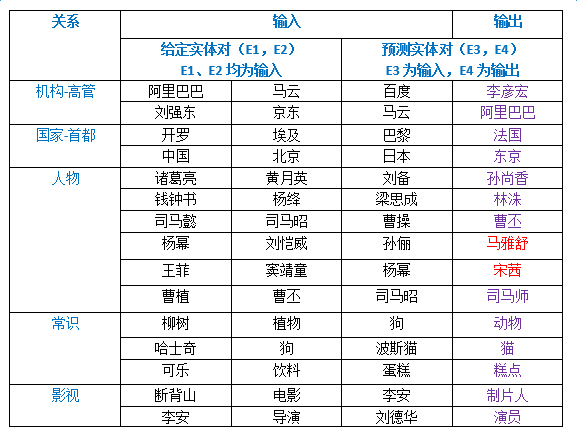
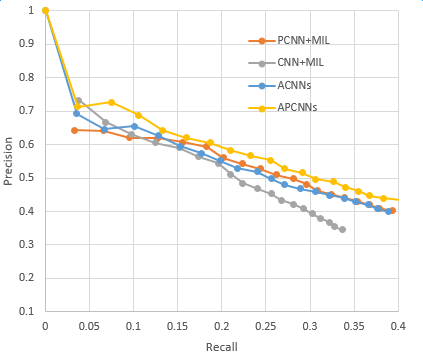
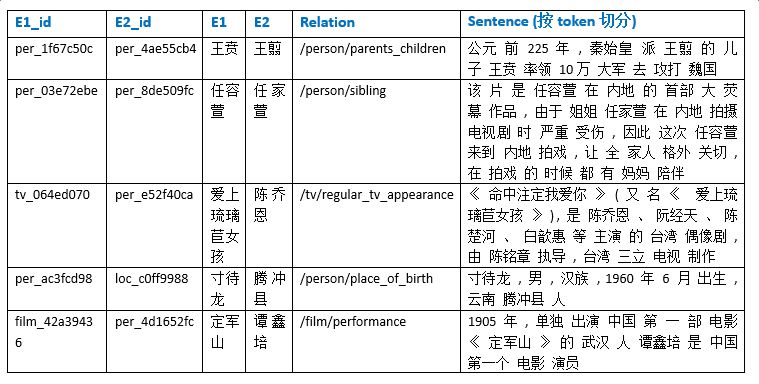
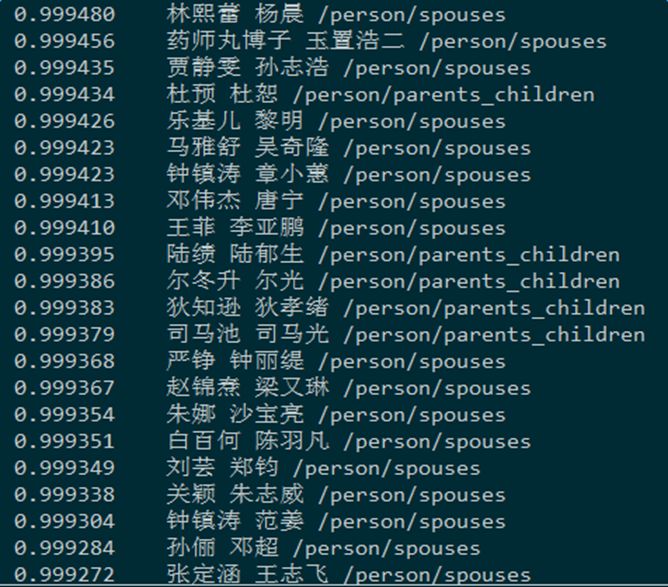
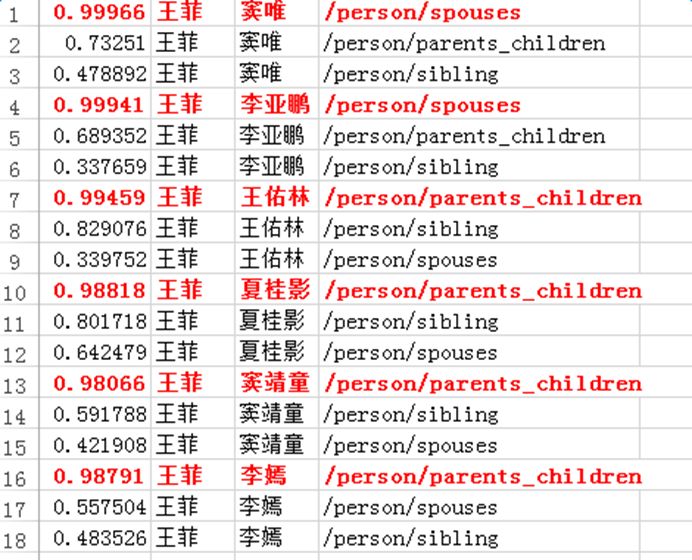
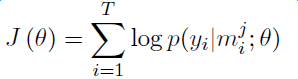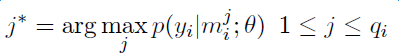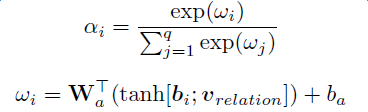Introduction to deep learning model The DeepDive system relies heavily on NLP tools during the data processing phase. If there are errors in the NLP process, these errors will be propagated and amplified in subsequent annotation and learning steps, affecting the final relationship extraction effect. In order to avoid this kind of communication and influence, in recent years, deep learning technology has begun to gain more and more attention and application in the relationship extraction task. This chapter mainly introduces a relation extraction method combining remote supervised annotation with a convolutional neural network based model and some improved techniques of the method. Piecewise Convolutional Neural Networks (PCNNs) model The PCNNs model was proposed by Zeng et al. in 2015 and proposes solutions for two problems: For the wrong label problem of remote supervision, the model proposes to use the multi-instance learning method to extract the training sample training model with high confidence from the training set. In view of the errors in the traditional statistical model feature extraction process and the subsequent error propagation problems, the model proposes to automatically learn the features using the piecewise convolutional neural network, thus avoiding complex NLP processes. The following figure is a schematic diagram of the PCNNs model: The PCNNs model mainly includes the following steps: Experiments have shown that the average value of the PCNNs + multi-instance learning method on Top N is 5 percentage points higher than that of the simple multi-instance learning method. Attention mechanism and other improvements The above model learns and predicts only one sentence for each entity pair, and loses a lot of information from other correctly labeled sentences. In order to more effectively utilize as many correctly labeled sentences as possible while filtering out the wrong label case, Lin et al. proposed the PCNNs+Attention (APCNNs) algorithm in 2016. Compared with the previous PCNNs model, the algorithm adds a sentence-level attention mechanism before the softmax layer after the pooling layer. The schematic diagram of the algorithm is as follows: In addition to the Attention mechanism, there are other auxiliary information that is also added to the multi-instance learning model to change the quality of the relationship extraction, such as adding entity description information when computing entity vectors (Ji et al., 2017); using external nerves Information such as the reliability of the data acquired by the network and the confidence of the sample guides the training of the model (Tang et al., 2017). The figure below shows the comparison between the accuracy and the recall rate of each model and the improved algorithm. Mintz does not deal with the wrong label problem of remote supervision, and directly trains with all the labeling examples. MultiR and MIML use the probability graph model for example screening. Two multi-instance learning models; PCNN+MIL is the model introduced in the first section of this chapter; APCNNs adds the attention mechanism to PCNN+MIL; PCNNs+D adds the use of descriptive information to PCNN+MIL; APCNNs +D adds the use of descriptive information to APCNNs. The experiment used the broader New York Times (NYT) dataset used in the field (Riedel et al., 2010). Progress in the application of deep learning methods in map construction The application of the deep learning model in the construction of Shenma knowledge map data is still in the exploratory stage. This chapter will introduce the current work progress and some problems encountered in the process of business landing. Corpus preparation and entity vectorization The deep learning model relies heavily on the accuracy of token vectorization. The same as the corpus preparation based on the DeepDive method, the token segmentation here is changed from the word unit to the entity unit, and the entity granularity identified by the NER link is taken as the standard. The ability of Word2vec to represent tokens is related to the comprehensiveness of the corpus and the size of the corpus. Therefore, we choose the encyclopedia full corpus as the training corpus of word2vec. The statistics and model parameters are set as shown in the following table: In order to verify the effect of word vector training, we have done a variety of tests on the results of word2vec, some experimental data is given here. The figure below shows an experiment for finding the most relevant entity given an entity: The following is an experiment to calculate one entity of a pair of entities and a pair of predicted entities, and to calculate another entity in the pair of predicted entities. Five kinds of prediction relationships were randomly selected, and 15 pairs of given entity pairs and predicted entity pairs were constructed. The prediction results are shown in the following figure. Except for the two examples of floating red, the other predictions are correct: Model selection and training data preparation In the specific application we chose to adopt the APCNNs model. We reproduced several key models mentioned in the previous chapter on the NYT standard dataset, including CNN+MIL, PCNN+MIL, CNNs (CNN model based on Attention mechanism) and APCNNs. The results of the recurrence are basically consistent with the baseline given in the paper. The performance of the APCNNs model is significantly better than other models. The following figure is a comparison of the call results of several models: In order to get rich training data, we take 15 core relationships in the knowledge map to build relatively perfect characters, geographic location, organization, film, television, books, etc., such as movie actors, book authors, company executives, people. Birthplace, etc., according to the encyclopedic corpus, the positive example is one of the 15 relations. The total number is in the order of 10 million, and the example with no relation value (relation value is NA) exceeds 100 million. Application attempts and problem analysis The APCNNs model is still in the trial stage in the construction of auxiliary knowledge map data. In terms of computing power, the APCNNs model has an advantage over the DeepDive system. It can calculate multiple relationships simultaneously on large-scale corpus, and the iterative update process does not require manual verification interaction. However, in the process of business landing, we also encountered some problems, summarized as follows: Large-scale experiments take too long, making it difficult to adjust parameters and iterate over each algorithm strategy. At present, the test corpus commonly used in academia is the NYT data set in English. When the same model is applied to Chinese corpus, there is a problem of difficulty in benchmarking the call rate. The process of deep learning is difficult to intervene manually. Suppose we want to predict the marriage relationship of (Yang Mi, Liu Weiwei), but from the initial generation of word vectors based on large-scale corpus, if the current dominant relationship in the corpus (Yang Mi, Liu Weiwei) is not a marriage relationship, but a film and television drama In the cooperation relationship (such as "The film tells Yang Mi's summer and evening in the embarrassing situation of friends calculation, boyfriend marriage, Liu Ziwei played by Liu Weiwei rescued, but it fell into a more trapped story."), Or based on the joint presence of certain activities (such as "Yang Mi and Liu Weiwei jointly served as the charity ambassador of the Sina Xiamen Love Library"), the relationship vector obtained in the attention step will be biased towards the cooperative relationship, which will lead to the calculation package. When the weight of each sentence is used, it is difficult to obtain a high score for a sentence expressing a marriage relationship, which leads to deviation in subsequent learning. The results of the deep learning model are more difficult to perform manual evaluation, especially for entity pairs that do not appear in the knowledge map. It is necessary to perform matching and extraction in a large-scale intermediate process matrix, and visualize the weight matrix as the score of each sentence in the package. Both computing resources and labor have no small consumption. Summary and outlook Both DeepDive-based methods and deep learning-based methods have their own advantages and disadvantages. The following two methods summarize and contrast these two methods: 1. Selection and scope of corpus Deepdive can be applied to smaller, more specialized corpora, such as the relationship mining of historical figures; adjustment rules can be adjusted for the characteristics of corpus and extraction relationships, such as one-to-one or one-to-many of marital relationships, such as the corpus of linguistics Habits and so on. The APCNNs model is suitable for large-scale corpus, because the premise that the attention mechanism can operate normally is that the entity vector learned by word2vec is rich and comprehensive. 2, relationship extraction Deepdive is only applicable to the judgment of a single relationship, and the classification result is the expected value of a relationship between entities. Different rules can be operated for different relationships, and the accuracy of labeling of training sets can be improved by rule-based labeling. The APCNNs model is suitable for multi-classification problems, and the classification result is the ordering of the relationship scores in the relation set. There is no need to do rule operations for a particular relationship in the relation collection. 3, long tail data Deepdive is more suitable for relation mining of long tail data. As long as it is a pair of entities that NER can recognize, even if the frequency is low, it can judge according to the context characteristics of the pair. The APCNNs model needs to ensure that the number of occurrences of the entity in the corpus is higher than a certain threshold, such as min_count>=5, to ensure that the entity has a vector representation of word2vec. There is a certain number of sentences in the bag, which is convenient for selecting high similarity for training. 4, the results of generation and detection Deepdive's judgment of the correctness of the output is only for a single sentence, and the same entity pair may give completely different prediction results in different sentences. The test needs to be combined with the original sentence to judge whether the result is accurate. The advantage is that the original sentence is used as a basis for manual verification. The APCNNs model makes judgments about specific entity pairs, and for a given entity pair, the system gives consistent output. For the correctness judgment of the result of the new data, it is necessary to combine the intermediate results to extract and verify the selected sentence set in the package, which increases the difficulty of the manual test. In the future work, for the DeepDive-based approach, we will expand the number of crawling relationships, consider streamlining and platform-improving the improved algorithms in business practice, and construct auxiliary information supplement tools to help mitigate the results of DeepDive. The manual inspection work in the process of writing the knowledge map, for example, for the entity pair of the marriage relationship, we can obtain the gender, birth date and other information of the character from the map to assist the correct judgment of the relationship. For the deep learning-based approach, we will invest more time and effort to try to promote business landing and model improvement from the following aspects: Apply some improved algorithms that have been proven effective by DeepDive to deep learning methods, such as filtering based on related keywords, reducing data size and improving operational efficiency. Visualize the intermediate results of the calculation, analyze the relationship between the relationship vector and the sentence selection in the attention process, try to establish the evaluation mechanism of the selection result, and try to use the richer information to obtain a more accurate relationship vector. Consider how to break through the limitations of pre-set relationship sets, extract relationships for open domains, and automatically discover new relationships and knowledge. Explore the extraction of relationships other than text, such as tables, audio, images, and more. 27 Inch Aio,All In One Pc 27 Inch,All In One Desktop Touch Screen,All In One Pc Touch Screen Guangzhou Bolei Electronic Technology Co., Ltd. , https://www.nzpal.com