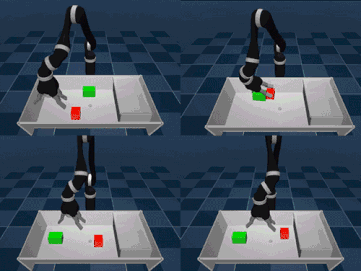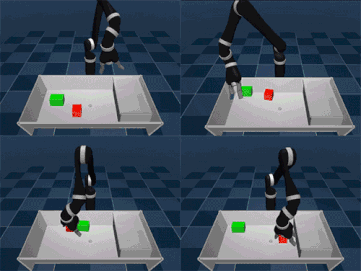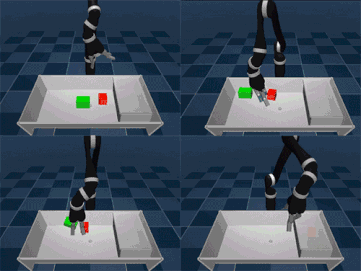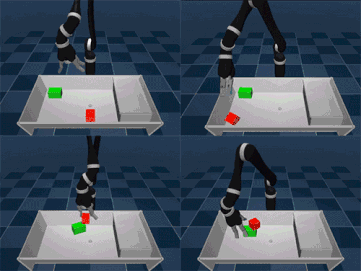
It's hard to get children (and adults) to organize things, but it's no small challenge to let AI organize things like people. Some of the core skills of visual movement are the key to success: approach an object, grab and lift it, then open a box and put it in the box. To complete more complex actions, you must apply these skills in the correct order. Controlling tasks, such as tidying up a table or stacking objects, requires the agent to decide how, when, and where to coordinate the six joints of the robotic arm and finger to move and achieve the goal. At a certain moment, there are many combinations of possible actions, and if you want to combine them in order, it creates serious problems - which makes reinforcement learning an interesting field. Similar reward shaping, apprenticeship learning, or learning from presentations can help solve the above problems. However, these methods require a good understanding of the task - learning complex control tasks with little prior knowledge remains an unsolved challenge. Yesterday, DeepMind proposed a new learning model called Planned Auxiliary Control (SAC-X) to solve the above problems. The working principle of SAC-X is that in order to master complex tasks from scratch, the agent must first learn to explore a series of basic skills and master them. Just as babies must learn to balance before learning to crawl and walk, let agents learn simple skills to enhance internal coordination and help them understand and perform complex tasks. The researchers experimented with the SAC-X method in some simulated environments and real robots, including stacking different target objects and tidying up the table (where moving objects are needed). The general principle of the auxiliary tasks they refer to is to encourage the agent to explore its sensing space. For example, activating a finger's tactile sensor, sensing the magnitude of the force at the wrist, maximizing the joint angle of the body sensor, or forcing the object to move within its visual camera sensor. If you reach the goal, each task will receive a simple reward, otherwise there will be no reward. The simulation agent finally mastered the complex task of "stacking" The agent can finally decide its own "purpose", that is, what to accomplish next, which may be an auxiliary task or an externally determined target task. Importantly, by extensive use of off-policy learning, agents can detect and learn from reward signals. For example, when picking up or moving a target object, the agent may inadvertently complete the stacking action, which will cause the reward to observe this action. Planning a goal is important because a series of simple tasks can lead to rare external rewards. It can create personalized learning courses based on the relevant knowledge collected. This has proven to be an effective way to develop knowledge in such a broad field, and this method is more useful when only a small number of external reward signals are available. Our agent determines the next target through the scheduling module. The scheduler is improved by the meta-learning algorithm during the training process. The algorithm tries to maximize the progress of the main task and significantly improve the data efficiency. After exploring some internal auxiliary tasks, the agent learned how to stack and clean up items. The evaluation of SAC-X indicates that SAC-X can solve problems from scratch using the same underlying auxiliary tasks. The exciting thing is that in the lab, the SAC-X can learn to pick and place tasks from zero on a real robotic arm. This has been difficult in the past because learning on a real robotic arm requires data efficiency. So people usually train a simulation agent and then transfer it to the real robot arm. Researchers at DeepMind believe that the birth of SAC-X is an important step in learning tasks from zero (just to determine the ultimate goal of the mission). SAC-X allows you to set up any auxiliary task: it can be a general task (such as activating a sensor), or it can be any task a researcher needs. In other words, in this respect, SAC-X is a general-purpose reinforcement learning method that can be widely applied to general sparse reinforcement learning environments in addition to control tasks and robot tasks. ShenZhen Haofa Metal Precision Parts Technology Co., Ltd. , https://www.haofametals.com