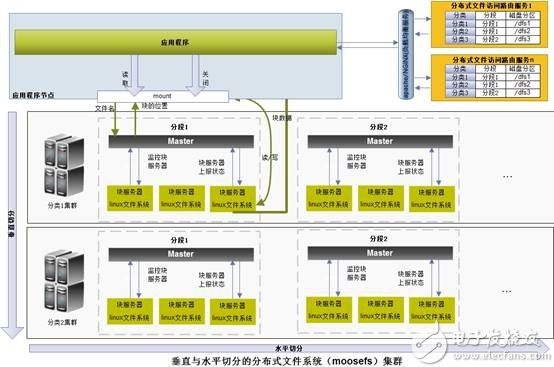
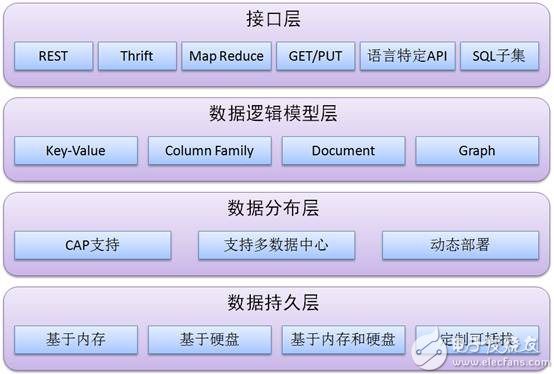
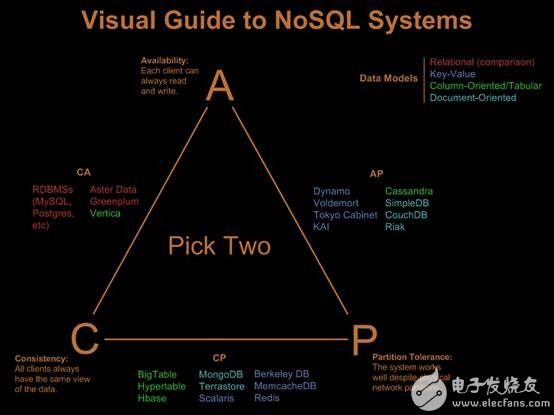
Distributed storage concept Unlike the current centralized storage technology, distributed storage technology does not store data on one or more specific nodes, but uses the disk space on each Machine in the enterprise through the network and spreads these. The storage resources constitute a virtual storage device, and the data is distributed and stored in all corners of the enterprise. Specific technology and application: Massive data is divided according to the degree of structure, and can be roughly divided into structured data, unstructured data, and semi-structured data. This article will next describe how these three types of data are distributed. Storage and application of structured data The so-called structured data is a user-defined data type, which contains a series of attributes, each of which has a data type, stored in a relational database, and can be used to express the implemented data in a two-dimensional table structure. Most systems have a large amount of structured data, which is generally stored in a relational database such as Oracle or MySQL. When the system is large enough to support a single node database, there are generally two methods: vertical expansion and horizontal expansion. · Vertical expansion: Vertical expansion is better to understand. Simply speaking, it is to divide the database according to function and store the data of different functions in different databases, so that a large database is divided into multiple small databases, thus reaching the database. Extension. An application system with well-designed architecture generally has a total function consisting of a number of loosely coupled functional modules, and the data required for each functional module corresponds to one or more tables in the database. The less interaction between the various functional modules, the more uniform, the lower the coupling degree of the system, the easier it is for such a system to achieve vertical segmentation. · Horizontal expansion: In simple terms, the horizontal segmentation of data can be understood as segmentation according to the data row, that is, some rows in the table are sliced ​​into one database, and some other rows are further divided into other databases. In the database. In order to be able to easily determine which database the data is split into, the segmentation always needs to be performed according to a specific rule, such as the range of a certain numeric field, the range of a certain time type field, or some The hash value of the field. Vertical expansion and horizontal expansion have their own advantages and disadvantages. Generally, a large system will combine horizontal and vertical expansion. Practical application: Figure 1 is an architectural diagram of structured data distributed storage designed for nuclear high-base projects. Figure 1 can be horizontal & vertical segmentation extended data access framework · A separate distributed data access layer is used, and the back-end distributed database cluster is transparent to front-end applications. · Integrate Memcached clusters to reduce access to back-end databases and improve data query efficiency. · Support both vertical and horizontal expansion methods. · Based on the globally unique primary key range segmentation method, the workload of subsequent maintenance is reduced. · The generation of globally unique primary keys uses DRBD+Heartbeat technology to ensure reliability. · Implement high-availability architectures with MySQL Replication technology. Note: The above data segmentation scheme is not the only way to extend MySql. Interested readers can pay attention to the MySQL-Clustrix Sierra distributed database system in the era of cloud computing. Storage and application of unstructured data Relative to structured data, data that is inconvenient to represent in a database two-dimensional logical table is called unstructured data, including office documents, text, images, XML, HTML, various reports, images, and audio in all formats. /video information and more. Distributed file system is the main technology to realize unstructured data storage. When it comes to distributed file system, it has to mention GFS (full name "Google File System"). The system architecture diagram of GFS is shown in the figure below. Figure 3 Google-file-system architecture diagram (detailed) GFS divides the entire system into three types of roles: Client, Master, and Chunk Server. Client (client): is the access interface provided by GFS to the application. It is a set of dedicated interfaces. It does not comply with the POSIX specification and is provided in the form of a library file. The application calls these library functions directly and is linked with the library. · Master (Master Server): A management node of GFS that stores metadata related to data files instead of Chunk. Metadata includes: Name Space, which is the directory structure of the entire file system, a table that maps 64-bit tags to the location of the data block and its constituent files, Chunk copy location information, and which process is reading and writing specific Data blocks, etc. Also, the Master node periodically receives updates ("Heart-beat") from each Chunk node to keep the metadata up to date. · Chunk Server: Responsible for specific storage tasks to store Chunk. GFS divides files into fixed sizes. The default is 64MB. Each block is called a Chunk. Each Chunk is divided into blocks by 64KB. Each Chunk has a unique 64-bit label. GFS uses a copy to achieve fault tolerance, and each Chunk has multiple storage copies (the default is three). There are many Chunk Servers, and the number directly determines the size of GFS. The reason why GFS is important is that after Google published the GFS paper, many open source organizations have developed their own distributed file systems based on GFS papers, among which HDFS, MooseFS, MogileFS, etc. are well known. Practical application: Due to the large amount of data and applications need to be stored in the nuclear high-base project in the future, we also adopt the distributed file system scheme when designing, because the open source distributed file system can basically meet our needs, and from time to time. It is also quite stressful, so we adopted the open source MooseFS as the underlying distributed file system. · MooseFS problem: Since MooseFS is also designed according to GFS papers, there is only one Master (main server). Although it is possible to add a backup log server, there is still a problem that the Master cannot expand, when the element is stored on a single Master node. When the data is more and more, the memory occupied by the master node will increase more and more until the upper limit of the memory of the server is reached. Therefore, the single master node has a memory bottleneck, can only store limited data, has poor scalability, and is unstable. . · Optimization of MooseFS: In the face of problems with MooseFS, we adopted a "Sharding" technology similar to distributed database, designed a distributed file system access framework, which can do vertical and horizontal cuts on distributed file systems. Minute. This maximizes the scalability and stability of the MooseFS system. The following figure is an architectural diagram of unstructured data distributed storage designed for nuclear high-base projects. We have designed two access methods, one is GFS-like API access, provided as a library file, and the application directly accesses the distributed file system by calling the API. The second is accessed through a RESTful web service. Figure 4 Horizontal and Vertical Segmentation Extended Distributed File System Access Framework (API version) Figure 5 can be horizontal & vertical split extended distributed file system access framework (RESTful web service version) Storage and application of semi-structured data Is the data between fully structured data (such as relational databases, object-oriented databases) and completely unstructured data (such as sounds, image files, etc.), semi-structured data models have a certain structure, But it is more flexible than traditional relationships and object-oriented models. The semi-structured data model is completely independent of the strict concept of traditional database schemas, and the data in these models are self-describing. Since semi-structured data does not have a strict schema definition, it is not suitable for storage with a traditional relational database. A database suitable for storing such data is called a "NoSQL" database. NoSQL definition: A database called the next generation, which is non-relational, distributed, lightweight, supports horizontal expansion and generally does not guarantee a data storage system that conforms to the ACID principle. "NoSQL" is actually a misleading alias, called Non Relational Database (non-relational database) is more appropriate. The so-called "non-relational database" refers to: · Use loosely coupled types, scalable data patterns to logically model data (Maps, columns, documents, charts, etc.) instead of using fixed relational schema tuples to build data models. · Designed to support horizontal scaling, following a CAP theorem (a guaranteed multi-node data distribution model that guarantees any two of consistency, availability, and partition tolerance). This means the necessary support for multiple data centers and dynamic provisioning (transparently adding/deleting nodes in production clusters), namely Elasticity. · Have the ability to persist data on disk or in memory, or both, and sometimes use hot-swappable custom storage. · Support multiple 'Non-SQL' interfaces (usually more than one) for data access. Figure 6 shows the overall architecture of NoSQL proposed by Sourav Mazumder: Figure 6 NoSQL overall architecture · Interfaces: REST (HBase, CouchDB, Riak, etc.), MapReduce (HBase, CouchDB, MongoDB, Hypertable, etc.), Get/Put (Voldemort, Scalaris, etc.), Thrift (HBase, Hypertable, Cassandra, etc.), language-specific API ( MongoDB). · Logical data model: for key-value pairs (Voldemort, Dynomite, etc.), for Column Family (BigTable, HBase, Hypertable, etc.), document-oriented (Couch DB, MongoDB, etc.), graph-oriented (Neo4j, Infogrid, etc.) · Data distribution models: availability and usability (HBase, Hypertable, MongoDB, etc.), usability and partitionability (Cassandra, etc.). The combination of consistency and zonability results in some loss of availability for some non-rated nodes. Interestingly, there is currently no "non-relational database" that supports this combination. Data persistence: memory-based (such as Redis, Scalaris, Terrastore), disk-based (such as MongoDB, Riak, etc.), or a combination of memory and disk (such as HBase, Hypertable, Cassandra). The type of storage helps us identify which type the solution is suitable for. However, in most cases it has been found that a solution based on a combined solution is the best choice. It supports high performance through in-memory data storage and can be stored on disk after writing enough data to ensure continuity. The important theoretical basis in NoSQL: CAP theory: · C: Consistency consistency · A: Availability Availability (refers to fast access to data) · P: Tolerance of network Partition Partition Tolerance (Distributed) Figure 7 CAP theory The principle of CAP tells us that these three factors can only satisfy at most two, and it is impossible to take care of all three. For distributed systems, partition tolerance is a basic requirement, so consistency must be abandoned. For large websites, the requirements for partition tolerance and availability are higher, so generally choose to give up the consistency. Corresponding to CAP theory, NoSQL pursues AP, while traditional database pursues CA, which can explain why traditional database has limited scalability. BASE model: It is interesting to say that the English meaning of BASE is alkali, and ACID is acid. It’s really not a fire. · Basically Availble – Basically available · Soft-state – soft state / flexible transaction · Eventual Consistency - Final Consistency The BASE model is the opposite of the traditional ACID model. Unlike the ACID model, BASE emphasizes the sacrifice of high consistency for availability or reliability. Basically available means that partial partitioning fails by Sharding. Soft state refers to asynchronous, allowing data to be inconsistent over time, as long as the final agreement is guaranteed. Final consistency is a core concept throughout NoSQL, emphasizing that the final data is consistent, not always consistent. Quorum NRW: Figure 8 Quorum NRW N: The number of nodes copied, that is, the number of copies of a piece of data. These three factors determine availability, consistency, and partition tolerance. Only W + R > N can guarantee strong consistency. Practical application: In the first half of this year, I was responsible for the design and development of Internet search in the aspire search team. I designed the web crawler system to use Cassandra to store web pages and link information. Let me talk about my views on Cassandra in combination with my practical experience: advantage: · Flexible extension: Since Cassandra is completely distributed, you don't need to design complex data segmentation schemes like MySQL, and you don't need to configure complex DRBD+Heartbeat. Everything is very simple, just need A simple configuration can add a new node to a cluster, and it is completely transparent to the client and does not require any changes. · Flexible schema: There is no need to pre-design the schema like a database. It is very convenient to add or delete fields. · Easy to use: Since there is no complicated query language like SQL, the learning cost is not high and it is easy to get started. Disadvantages: · Poor stability: During our actual use, we found that the amount of data on a single machine reached more than 200G, and the phenomenon of downtime occurred from time to time. · Lack of management and analysis tools: Traditional relational data has useful management and analysis tools that make it easy to manage databases, view data, analyze performance bottlenecks, and Cassandra does lack similar tools, even A simple view of a piece of data must be programmed to see.
Other PCD tools have extremely high hardness and wear resistance, low friction coefficient, high modulus of elasticity, high thermal conductivity, low coefficient of thermal expansion, and low affinity with non-ferrous metals. It can be used for precision machining of non-metallic hard and brittle materials such as graphite, high wear resistant materials, composite materials, high silicon aluminum alloys and other ductile non-ferrous materials. There are many types of diamond tools, and the performance difference is significant. The structure, preparation method and application fields of different types of diamond tools are quite different.
Our customers can depend on us for prompt, efficient response and quality products that attest to our expertise in engineering and manufacturing. As part of our scrupulous inspection procedure, we test 100% of our drills .375" and under for assembly integrity, leakage, and specified oil flow.
Other PCD TOOLS :
PCD carving tool
PCD Drills
Flexible in order quantity:
Samples can be provided before mass production, and MOQ can be discussed accordingly.
PRODUCT DETAIL:
PRODUCTING PROGRESS:
PAYMENT AND DELIVERY:
PRODUCT EQUIPMENT :
ABOUT US :
We are specialize in manufacturing PCD diamond tools and Carbide tools. Our major product inclulde PCD Inserts , PCD Reamers , PCD End Mills, PCD Taps, Cabide Inserts,Carbide Drills, Carbide Reams, Taps etc.,
We also offered customized cutting tools per drawings, and provide package according to customer requirements. We manufacture a series range of cutting tools for machining of Cast iron, Aluminium alloy and Non-Ferros metal, it is widely used in all major sectors like Automobiles, Engineering, Aerospace, Aviation and 3C industry. Premium quality of raw material is used in the production and strict examination during processing with advanced equipment, so our client are satisfied with our reliable quality and on-time delivery.
Our best selling of cutting tools include PCD Inserts, PCD End Mill, PCD Ball Nose Mill, PCD Reamer, Carbide Taps , Carbide End Mill, Special Form Cutter and many more. For these years we have been made a large forward in the technologies of manufacturing cutting tools. With high quality on performance and price, our product sells well both on domestic and overseas market. And we will always focus on the quality and best service, to make long business relationship.
quanlity control:
We have dedicated team of quality control and precise equipment to keep good and stable performance for our products and processing services.
Boring Cutter,Lathe Turning Tools,End Mill Drill Bit,Carbide Drill OPT Cutting Tools Co., Ltd. , https://www.optdiamondtoolss.com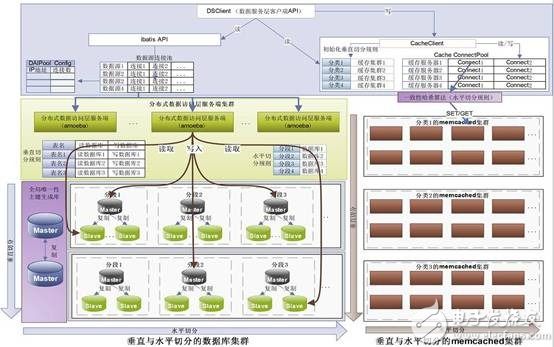

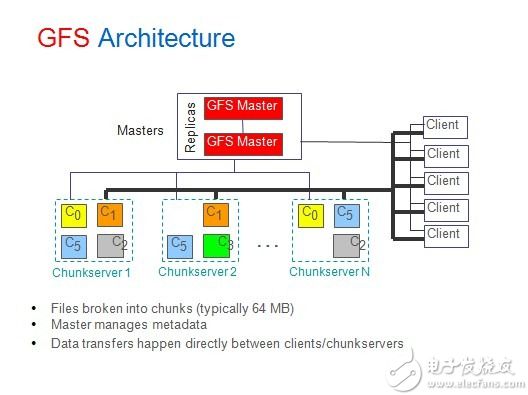
Figure 2 Google-file-system architecture diagram 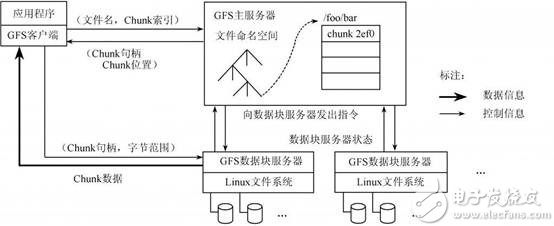


R: The minimum number of nodes for a successful read operation, that is, the number of copies required for each read success.
W: The minimum number of nodes for successful write operations, that is, the number of copies required for each write success.












