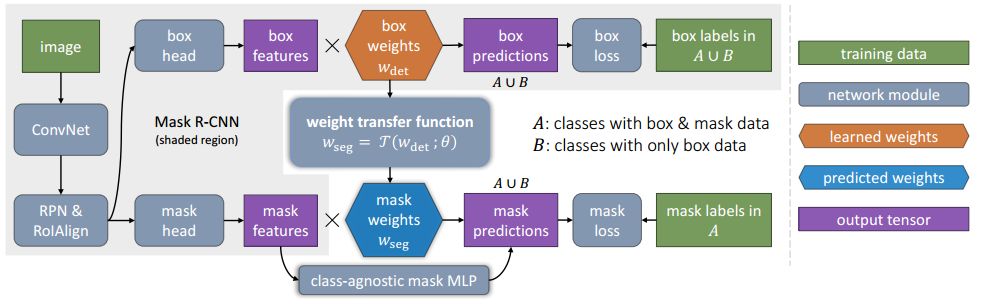
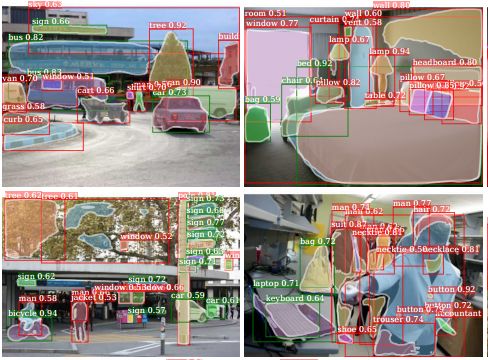
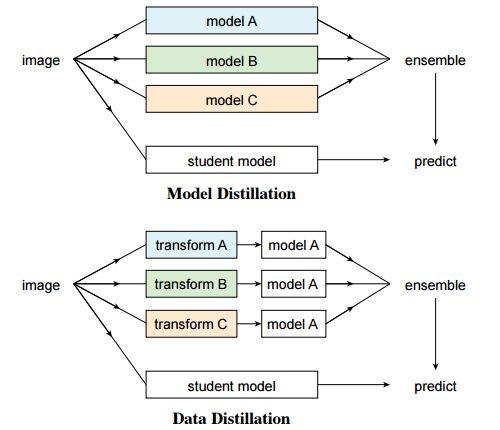
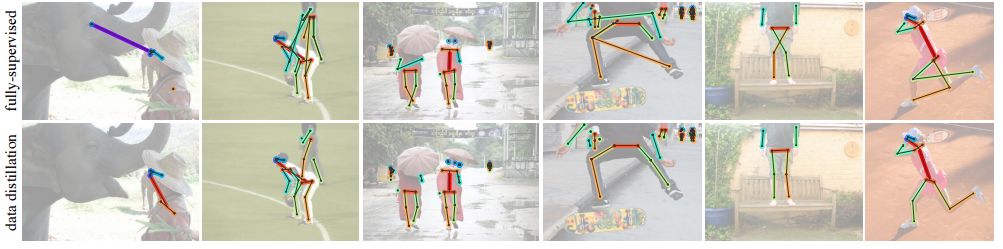
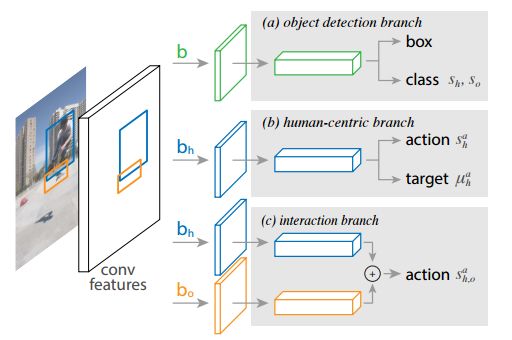
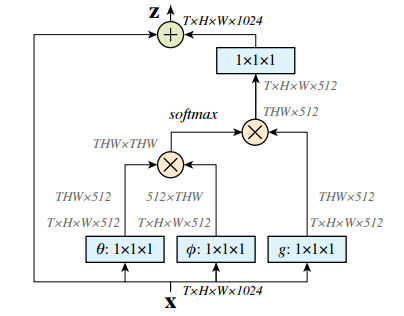
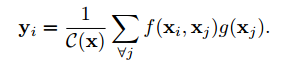The annual CVPR is here, and all kinds of cutting-edge, novel, and amazing results will bring us a new understanding. Can't help but want to pay attention to the outstanding work of the great gods. Among them, Kaiming, who has won two CVPR best papers, is the first object to be retrieved. In this year's main forum, a total of four papers appeared in the figure of Kaiming He, they are: In the field of image segmentation: Learning to Segment Every Thing; Omnidirectional supervised learning using data distillation: Data Distillation: Toward Omni-Supervised Learning; Research human-object interaction: Detecting and Recognizing Human-Object Interactions; A non-local neural network result: Non-Local Neural Netwroks. (Another famous rbg Daniel is also the co-author of these four papers >> http: //) Let's learn the subtle ideas in these four papers together! One of the most interesting tasks in object detection is to predict the foreground mask of the detected object. This task, called instance segmentation, can accurately predict the pixels contained in each object. But in practice, the system contains only a small class of objects in the visual world, and the target classification in about 100 limits its application. This is mainly because advanced instance segmentation algorithms require strong supervised samples for training. The current training data category is limited and adding a new category of strongly supervised instance segmentation samples is very time-consuming and labor-intensive. But on the other hand, the samples marked by the bounding box are very rich and easy to obtain. So the researchers came up with an idea: Is it possible to generate high-quality segmentation models that are valid for all classes without relying on complete instance segmentation labels? Under the guidance of this idea, this paper introduces a new partially supervised instance segmentation task and proposes a novel transfer learning method to solve this problem. This new semi-supervised problem is defined as follows: 1. The training data contains many types of objects, only a small subset of categories have instance mask labels and the rest only have bounding box labels; 2. The instance segmentation algorithm needs to fully utilize these data Generate a model that can segment prediction instances for all categories in the dataset. Since the training data is a mixture of strong mark (mask) and weak mark (frame) data, this task is called partial supervised learning. The main advantage of some supervision tasks is that through the exploration of the existing small-class mask marking data and the large-scale border-marking data, a large-scale instance segmentation model can be established to expand the advanced models that perform well in small categories to Thousands of categories are selected, which is essential for practical use. In the specific implementation process, a novel transfer learning method is proposed based on Mask R-CNN. Mask R-CNN can decompose the instance segmentation problem into two sub-tasks: frame target detection and mask prediction. The classification information will be encoded into the frame header unit during training, and this visual category information can be transferred to the partially supervised mask header. Secondly, the author also proposed a unit called weight transfer function to predict the segmentation parameters of each category from the border parameters. When predicting, it will be used to predict the parameters of instance segmentation for each type of object, including categories that are not masked during training. The green box in the figure indicates the category with mask marks and the red box indicates only the border marks, and then the mask type is predicted. Finally, by learning the weight transfer function from the border to the segmentation in the small category, we successfully achieved partial supervised learning through the training of mixed data, and extended the powerful image segmentation model to 3000 types of objects. It also opened up the research direction of large-scale instance segmentation under non-full supervision. Paper >> http://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Learning_to_Segment_CVPR_2018_paper.pdf This article is also about the work of making full use of data. It explores a mechanism called omni-directional supervised learning to make the model use labeled data as much as possible, and provides potentially unlimited unlabeled data. A special area of ​​supervised learning. However, most researchers currently study semi-supervised problems by separating labeled and unlabeled data from labeled data to simulate such a data set. This method determines the upper limit of fully supervised learning using all labeled data. The omnidirectional supervised learning is to use the accurate results obtained from all the labeled data as the lower limit of the model to explore the possibility of exceeding the fully supervised learning baseline. Inspired by the idea of ​​model refining, this article proposes a method of data distillation to deal with the problem of omnidirectional supervision. First, a model trained with large-scale labeled data is used to create labels for unlabeled data; then the newly obtained label data is used to train a new model with the original data. In order to avoid that the data labels predicted by the model are meaningless, the single model used by the researchers processes the unlabeled data after different transformations (flip and scale transformation) and combines their results, and enhances the accuracy of the single model through data changes. Experiments show that such transformations can provide unusual information. In other words, compared with the prediction method that uses multiple models to refine knowledge, this method uses a single model to perform data distillation on unlabeled data under different changes. Due to the rapid development of fully supervised learning models, the current model produces fewer and fewer errors, and the prediction results for unknown data are becoming more and more credible. Therefore, data distillation does not need to change the recognition model, and can be used for large-scale processing of large-scale unlabeled data. In order to verify whether the data distillation for omnidirectional supervised learning is effective, the human key point detection task was evaluated on the COCO dataset. Through the original labeled COCO data set and a large-scale non-labeled data set (Sports-1M), the data was rectified and the Mask R-CNN model was trained. Annotations generated by the model on unlabeled data Through the rectification of unlabeled data, the researchers observed a significant improvement in the accuracy of the retained verification set: for the benchmark Mask R-CNN, the two-point AP was improved; as a reference, the manual labeling data using the same data volume was The improvement of 3 points indicates that the method of this article is hopeful to use unlabeled data to improve the model performance. Results achieved using data distillation To sum up, this article mainly explores the possibility of using omni-supervised methods to surpass large-scale fully supervised learning, using all supervised data and unsupervised data to achieve rectification. Paper >> http://openaccess.thecvf.com/content_cvpr_2018/papers/Radosavovic_Data_Distillation_Towards_CVPR_2018_paper.pdf The third article proposes a human-centered idea, using people appearing in the image as a powerful clue to determine the objects to interact with, and based on this idea, a model called InteractNet was developed to detect triplets , To achieve the detection and recognition of interaction between people and things. In the visual task, to understand what is happening in the image, in addition to detecting the objects, it is also necessary to recognize the relationship between the objects. This article focuses on solving the interaction between people and things. Recognizing the interaction between people and things can be expressed as a process of detecting triples. A large part of the pictures on the Internet contain characters, so human-centered understanding has great practical significance. In fact, in the eyes of the researchers, the tasks in the pictures provide a wealth of action information and connect objects interacting with them. But for the fine-grained human behavior and the interaction of multiple types of object recognition, it is still facing a series of challenges compared to simple object detection. The researchers found that the behavior and posture of the characters in the picture contain a lot of position information of the objects they interact with, so the search range of related objects based on this premise can be greatly reduced. Although a large number of objects are detected in each image, the target position predicted by the human body can help the model quickly find the target object related to a specific action. The researchers called this idea "human-centric" recognition and implemented it using the Faster R-CNN framework. Specifically, in the ROI related to characters, this branch implements behavior classification and density estimation of behavior target objects. The density estimator generates a four-dimensional Gaussian distribution, and for each behavior model will associate the position of the target object with the person. This artificial recognition branch and another simple dual interaction branch form a multi-task learning system, and can be jointly optimized. Three-branch architecture based on faster R-CNN The author finally conducted an evaluation on the V-COCO data set and achieved a 26% AP (31.8 to 40.0) improvement, which mainly came from using the target position related to the character. At the same time, this model called InteractNet achieved a 27% improvement on the HICO-DET dataset. The speed of 135ms / image is achieved in complex tasks, which has potential practicality. Estimation of target area related to motion Some results show For details of implementation, please see the specific description in the paper: http://openaccess.thecvf.com/content_cvpr_2018/papers/Gkioxari_Detecting_and_Recognizing_CVPR_2018_paper.pdf The fourth paper proposes a non-localized operation unit to obtain long-range dependence information. With the help of this building unit, the model can achieve very good performance in video classification tasks and static target detection tasks. In deep neural networks, long-range dependent capture is very important. For sequence data, recursive operations are generally used, while for image data, large receptive fields are realized by stacking deep convolution operations. However, the convolution and recursion operations are mainly used to process spatio-temporal local information, so long-range (large-range) dependencies can only be obtained by repeating the operation and gradually spreading the signal. Such repetitive operations will bring a series of limitations: first, the computational efficiency is low; second, it causes optimization difficulties; and finally, such a method makes it difficult to handle multiple reflection-dependent models that transfer information back and forth between different nodes. In order to overcome these difficulties, the author proposes a non-local operation in this article, which is used as an efficient, convenient and general module for deep neural networks to extract long-range dependencies. This operation is a generalization of the traditional non-localized mean operation. It calculates the response of a location by weighting all the location features of the input feature map, and these locations can be spatial, temporal, or spatio-temporal related, so it is applicable. For the processing of images, sequences and video signals. The advantages of non-local operations include the following three aspects: first, compared with the gradual propagation process of convolution and recursion, non-local operations can directly capture long-range features by calculating the interaction between positions; second, the efficient operation is A few layers of models can also achieve very good results; in the end it can adapt to varying size inputs and be easily integrated into other operations. In video, pixels have long-range spatial and temporal correlations, and a single non-local unit can directly capture these spatio-temporal correlations in feedforward. The accuracy of the non-local neural network constructed by a few non-local units to process the video is better than the traditional 2D / 3D convolutional network. At the same time, non-local neural networks are more economical than 3D convolution calculations. The mathematical representation is as follows: x is the input signal (image, video, sequence, feature, etc.) y is the output signal of the same size, i represents the index of position i in the output result, which is calculated from the response results of all possible positions j. Where f is used to calculate the relationship between positions ij, and g is used to calculate the representation of the input signal at position j. C represents the normalized function of the response. The structure of its space-time calculation unit is shown below: The input is a feature tensor, where g can be realized by 1 * 1 convolution, and the function of calculating the correlation can be realized by Gaussian and embedded Gaussian. Softmax is used here for normalization. For specific implementation, please refer to the paper, which describes the realization of each step in the formula including the dot product of f, mutual connection, and the implementation of non-localized units. In the Kinetics and Charades datasets, using only RGB images without using various fancy techniques, this method can obtain results that are comparable (or even better) to the current best algorithms. At the same time, this method can improve the accuracy of the three tasks of target detection, segmentation and pose estimation on the COCO data set, and only few external calculations need to be introduced. The processing of video and images proves that non-localized operations are universal and will become the basic building blocks of deep networks. Paper >> http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.pdf In addition, Kaiming will bring a tutorial called Visual Recognition and Beyond at this year's CVPR, which covers the cutting-edge research field of visual recognition and its application in advanced tasks. Kaiming, Ross Girshick, Alex Kirillov will explain the methods and principles of image classification, target detection, instance segmentation and semantic segmentation support from different perspectives, and then Georgia Gkioxari and Justin Johnson will explore behavior-based and inference-based visual recognition in two reports New mission. Interested friends can follow: https://sites.google.com/view/cvpr2018-recognition-tutorial http://kaiminghe.com/ In addition, after querying from the website of Facebook Research, it was found that CVPR has received a total of 28 papers in the past few years. In addition to the above four, the articles in various fields are as follows. Interested partners can conduct more in-depth learning. (Click on the picture to enlarge) Solar Panel,Pv Power Kit,Solar Power System,Home Solar Power System Wuxi Doton Power , http://www.dotonpower.com