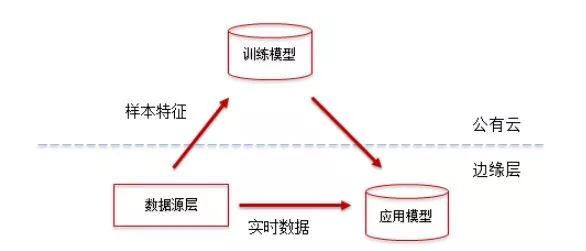
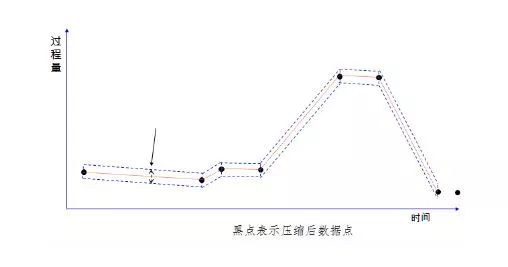
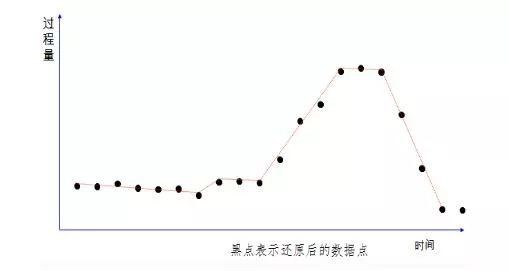
1. The scope of industrial big data Industrial big data includes manufacturing enterprise informatization data, industrial Internet of things data, and external cross-border data. Informatization data includes information such as customer orders and production plans in ERP. Industrial Internet of Things data mainly includes various production and quality consumption data collected from production equipment and operation and maintenance data obtained from smart products, while external cross-border data Including environmental data, market data and competing product data, among which the proportion of data obtained from machinery and equipment will become larger and larger. In addition to the 4V of big data (large amount of data, multiple types, low value density, and fast speed), the characteristics of industrial big data also have specialization, relevance, and timing characteristics. Industrial big data should pay attention to the physical meaning behind the features and the mechanism logic of the correlation between the features. The big data on the Internet can only be mined and related to the data itself, regardless of the meaning of the data itself. The result of the mining is the result. . The mining of industrial big data must have clear mining goals, and gradually expand the direction of mining on this basis for application functions. 2. Why is the weight of big data going to the cloud to be lightweight? When building a big data analysis system, a manufacturing company can not only adopt the traditional self-built data center architecture, but also use data storage and analysis to build on a public cloud platform, use offline training models, and combine edge computing to use real-time data and existing data at the production site. The trained model is a two-level architecture for business applications. The advantages of the two-level architecture are mainly reflected in the following four aspects: 1. Reduce storage costs: The data points collected from the device sensors are often sequential and continuous process quantities. With the increase of the collection frequency and the extension of the cycle, the amount of data is very large. If you consider the storage, backup and Restoring the management of the full life cycle is often cheaper on the public cloud. 2. Improve flexibility: processing big data on the public cloud requires high space and time flexibility. The requirements for data storage and computing resources will become higher and higher as the project time becomes longer and longer, while the public cloud is basically capable Do it when you want it, and you want it as much as you want. 3. Improve disaster tolerance: Traditional data center disaster tolerance backup usually adopts two places and three centers. In order to ensure the high availability of the 7*24 system, the system has high requirements, while the public cloud IaaS and PaaS disaster tolerance backup The mechanism can achieve low cost, low data loss rate and shorter recovery interval. 4. Data sharing is more convenient: companies should regard themselves as part of the "big data" value chain, so companies are both contributors and beneficiaries, and the value of industrial big data can be shared for upstream and downstream use of the company, using a unified public cloud The platform promotes the integration of data resources and makes data sharing more convenient. After big data goes to the cloud, due to the limitations of network bandwidth, high requirements for timeliness of data processing, data storage costs, and the complexity of model training, some lightweight processing of raw data at the edge of the enterprise is also required. Reduce the amount of original data based on the loss of the value of big data. Three, lightweight method Lightweighting is to reduce the amount of data for network transmission, storage, and training without losing the value of big data, not to eliminate abnormal data. In traditional instrument data collection, there is an operation to filter abnormal data, and a certain threshold will be set to remove abnormal jumps in the meter readings. The lightweight method does not use this method to remove abnormal data, because abnormal data has May be valuable for business analysis. The lightweight method is to discover and extract data based on value demand by business analysts, mainly through two methods: feature selection in sampling and data compression. Feature selection is to select the best subset with strong predictive ability from the collection of sample features that can be collected, eliminate repetitions, and simplify the correlation between multiple features. First, you can do a correlation analysis on multiple features. If the correlation of the features is 1, it means that the changes of the two features are exactly the same. By finding the linear relationship between the two features, one can restore the other feature through one feature. Simple example If the Chinese name of a product is required to be unique, then the correlation between the Chinese name of the product and its code is 1. If there are no products with multiple codes with the same name, then data collection, transmission, storage and You only need to keep the product code during training, and you only need to find out the product name through the correspondence table when the results are displayed. If there are clear requirements for the feature dimension when training samples, PCA method can also be used to reduce the feature dimension. PCA replaces the original n features with a smaller number of m features, mapping from old features to new features Capture the inherent variability in the data, and try to make the new m features independent of each other. There are also special rules to follow between some features. For example, the relationship between the shifts and shifts produced by a certain machine is completely arranged according to the four shifts three operation mode. At this time, you only need to confirm the shifts to deduce the execution shifts. Information, if such rules are fixed, features can be processed directly during model training, without the need for additional collection and storage. The use of compression algorithms is also a commonly used lightweight method. In the time-series continuous variable collection with time stamps, the amount of data increases as the collection frequency increases. It can be processed through deviation detection and compression filtering by Luo Xuanmen, both It can reflect the actual trend of the data, and the data that needs to be collected, transmitted and saved is also significantly reduced. The following three pictures briefly show the process of data compression. The self-encoding neural network combines the above two methods. The self-encoding neural network can not only reduce the dimension of the feature, but also compress the data through the encoding method. The self-encoding neural network is an unsupervised learning algorithm. It uses a back propagation algorithm and makes the target value equal to the input value. The purpose of data compression can be achieved by setting the number of hidden layer nodes in the neural network. For example, if we have 100 input features, we can set the number of hidden layer nodes to 50, and the final output layer will restore 100 input features. After the model training is completed, we can use the input layer to the hidden layer of the model as the compression algorithm, and the hidden layer to the output layer of the model as the decompression algorithm, so that the model is deployed at the edge layer for compression, and the model is used for decompression in the public cloud. Compared with PCA, self-encoding neural network can better deal with the nonlinear relationship between features. Fourth, the conclusion When more and more manufacturing industries put big data in the cloud for processing, and when the network, storage, and computing capabilities are effective, the method of data compression and data feature selection is used for data lightweight processing. In order to meet the data business analysis needs and the efficiency of processing efficiency.
The TPU materials type raw cable jacket can guarantee longer lifetime and quality. Coiled cable can be used to carry electrical currents as well as data and signal for telecommunications applications. This versatility makes coil cords ideal for use in environments that are often too rough for non-coiled cable.
It has the ability to extend beyond the natural length at rest, which can be a real space-saving feature. These cords are flexible beyond simple extending and retracting in that they can also be pulled, bent, and twisted without experiencing the metal fatigue of a straight cable.
Flex Coiled Cable Assembly, coiled cable harness, flex coiled wiring cable,High Quality Electrical Wire Harness,light-duty coiled cables ETOP WIREHARNESS LIMITED , https://www.etopwireharness.com