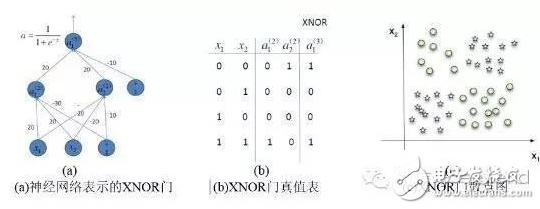
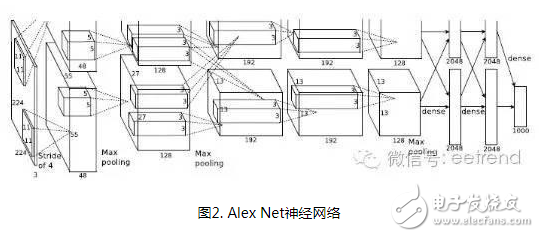
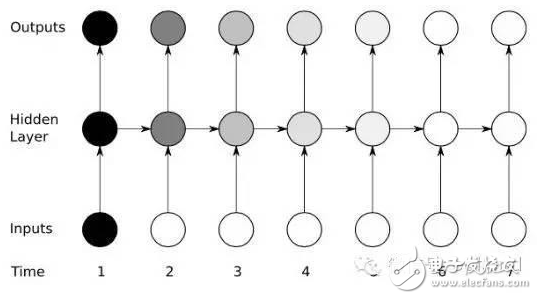
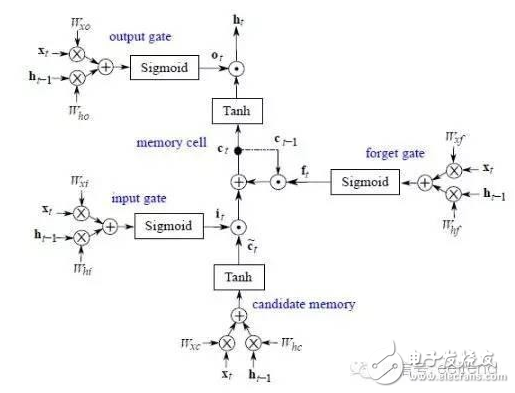
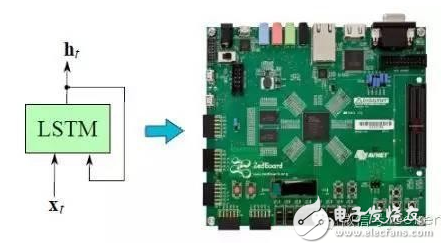
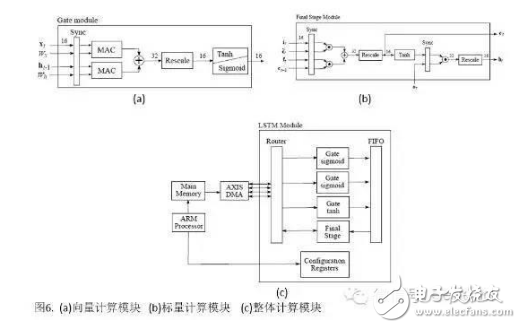
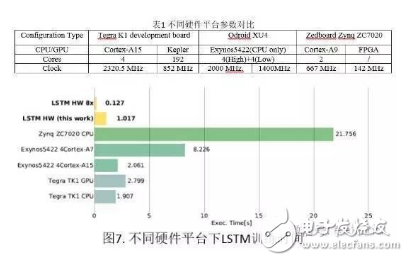
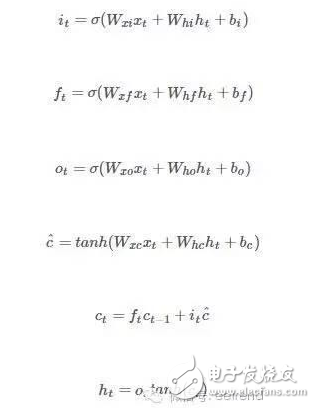In the past ten years, artificial intelligence has reached a stage of rapid development. Deep learning has played a mainstay role in its development. Despite its powerful simulation and prediction capabilities, deep learning still faces the problem of large amounts of calculations. At the hardware level, GPUs, ASICs, and FPGAs are all solutions to the huge amount of computation. This article will explain the respective structural characteristics of deep learning and FPGA and why it is effective to use FPGA to accelerate deep learning, and will introduce a recurrent neural network (RNN) implementation scheme on the FPGA platform. Deep learning is a field of machine learning, which belongs to the category of artificial intelligence. Deep learning mainly studies the algorithms, theories and applications of artificial neural networks. Since Hinton and others put it forward in 2006, deep learning has developed rapidly, and has achieved extraordinary achievements in natural language processing, image processing, speech processing and other fields, and has received great attention. In the era when the concept of the Internet is generally concerned by people, the impact of deep learning on artificial intelligence is huge, and people will feel incredible for its hidden potential and wide-ranging application value. In fact, artificial intelligence is a concept put forward in the last century. In 1957, Rosenblatt proposed the perceptron model (Perception), which is a two-layer linear network; in 1986, Rumelhart et al. proposed a back propagation algorithm (Back PropagaTIon) for the training of a three-layer neural network to optimize training Neural networks with huge parameters become possible; in 1995, Vapnik and others invented Support Vector Machines (Support Vector Machines), which demonstrated its powerful ability in classification problems. The above are all representative events in the history of artificial intelligence. However, limited by the computing power at the time, AI will always fall into a gloomy time after a period of high light-called: "AI Winter". However, with the improvement of computer hardware capabilities and storage capabilities, coupled with huge data sets, now is the best time for the development of human AI. Since Hinton proposed DBN (Deep Belief Network), artificial intelligence has been developing rapidly. In the field of image processing, CNN (Convolutional Neural Network) has played an irreplaceable role. In the field of speech recognition, RNN (Recurrent Neural Network) has also performed remarkable. The technology giants are also stepping up their steps. Google’s leading figure is Hinton, whose main event is Google brain, and last year it also acquired DeepMind, which uses AI to defeat humans in games; Facebook’s leading figure is Yann LeCun, and also formed In Facebook’s AI laboratory, Deepface’s face recognition accuracy rate reached an astonishing 97.35%. The domestic giant is Baidu, who hired Stanford University professor Andrew Ng (co-founder of Coursera) and established it. After the Baidu Brain Project, Baidu's performance in the field of speech recognition has been very strong. To put it simply, the classification of deep learning and traditional machine learning algorithms is consistent, mainly divided into supervised learning (supervised learning) and unsupervised learning (unsupervised learning). The so-called supervised learning means that the output is labeled learning, allowing the model to converge to the target value iteratively through training; unsupervised learning does not require human input labels, and the model discovers the structural features of the data through learning. The more common supervised learning methods include logistic regression, multi-layer perceptrons, and convolutional neural networks; non-supervised learning mainly includes sparse encoders, restricted Boltzmann machines, and deep confidence networks. All of these are achieved through neural networks, they are usually very complex structures, and there are many parameters that need to be learned. But neural networks can also do simple things, such as XNOR gates, as shown in the figure. In Figure 1(a), the two inputs x_1 and x_2 are each represented by a neuron, and a neuron as a bias (bias) is added to the input, and the parameters are learned through training, and finally the parameters of the entire model Convergence, the function is exactly the same as the truth table in Figure 1(b). Figure 1(c) Classification results. Generally speaking, the models are more complex. For example, Alex Net built by Krizhevsky and others in the ILSVRC 2012 Image Recognition Competition. They built a total of 11 layers of neural networks (5 convolutional layers, 3 fully connected layers, and 3 pooling layers), with a total of 650,000 neurons, 60 million parameters, and finally reached 15.2% recognition The error rate is much ahead of the 26.2% of the second place. The current popularity of deep learning is due to the improvement of big data and computing performance. But it still suffers from the bottleneck of computing power and data volume. In response to the demand for data volume, experts can alleviate model adjustments and changes, but there is no shortcut to the challenge of computing power. IFLYTEK, Baidu, Alibaba, and 360 also face computational difficulties in deep learning. The deep learning platform of iFLYTEK is a computationally intensive platform. It is a structure similar to supercomputing to realize high-speed interconnection between hundreds of machines in a cluster, but it is not a very typical supercomputing. HKUST iFLYTEK first explored the traditional way, using a large number of CPUs to support large-scale data preprocessing, and running the training of classic models such as GMM-HMM. The effect was not good under the thousands of hours of data. And 360 processes hundreds of millions of data every day, with more than 500,000 parameters. If a CPU is used, each model training will take a few days. This is simply unacceptable for the operation of Internet companies that advocate fast iteration. FPGA (Field Programmable Gate Array) is a product of further development on the basis of programmable logic devices such as PAL, GAL, and CPLD. It emerged as a semi-custom circuit in the field of application specific integrated circuits, which not only solves the shortcomings of fully customized circuits, but also overcomes the shortcomings of the limited number of gate circuits of the original programmable logic device. The development of FPGA is very different from the development of traditional PC and microcontroller. FPGA is mainly based on parallel operation and implemented by hardware description language; compared with PC or single-chip microcomputer (whether it is von Neumann structure or Harvard structure), the sequential operation is very different. FPGA development needs to start from many aspects such as top-level design, module layering, logic implementation, and software and hardware debugging. FPGAs can be programmed repeatedly by programming bitstream files. At present, most FPGAs use a lookup table structure based on SRAM (StaTIc Random Access Memory) technology, which is achieved by programming bitstream files to change the lookup table content. Configuration. Several hardware that can implement deep learning algorithms are discussed below. Use CPU. In 2006, people still used serial processors to deal with machine learning problems. At that time, Mutch and Lowe developed a tool FHLib (feature hierarchy library) to process hierarchical models. For the CPU, the amount of programming it requires is relatively small and has the benefit of transferability, but the characteristics of serial processing have become its shortcomings in the field of deep learning, and this shortcoming is fatal. Today, according to 2006, ten years have passed. The development of integrated circuits in the past ten years still follows Moore's Law. The performance of CPU has been greatly improved. However, this has not allowed the CPU to enter the deep learning research again. Vision. Although the CPU can have a certain degree of computing power on a small data set, and multi-core allows it to be processed in parallel, this is still far from enough for deep learning. Use GPU. The GPU has entered the eyes of researchers. Compared with the CPU, the number of cores of the GPU has been greatly increased, which also gives it more powerful parallel processing capabilities, as well as more powerful data flow control and data storage capabilities. Chikkerur made the difference between CPU and GPU in processing target recognition ability, and the final processing speed of GPU is 3-10 times that of CPU. Use ASIC. Application-specific integrated circuit chip (ASIC) is a more efficient method than GPU due to its customized characteristics. But its customization also determines its low portability. Once dedicated to a designed system, it is impossible to migrate to other systems. Moreover, its high cost and long production cycle make it not considered in the current research. Of course, its superior performance can still be competent in some areas. The ASIC solution is used, and the recognition rate can reach 60 frames per second in a 640×480pixel image. Use FPGA. FPGA has made a trade-off between GPU and ASIC, and it takes into account the processing speed and control ability. On the one hand, FPGA is a programmable and reconfigurable hardware, so it has more powerful controllability than GPU; on the other hand, with the increasing gate resources and memory bandwidth, it has a larger design space. What's more convenient is that FPGA also eliminates the tape-out process required in ASIC solutions. One disadvantage of FPGA is that it requires users to be able to program it in a hardware description language. However, some technology companies and research institutions have developed easier-to-use languages. For example, Impulse Accelerated Technologies Inc. has developed C-to-FPGA compiler to make FPGA more suitable for users. Yale’s E-Lab has developed Lua scripting language. . These tools shorten the researcher's development time limit to a certain extent and make the research easier and easier. Introduction to LSTM The traditional RNN consists of a three-layer network: the input layer it, the hidden layer ht, and the output layer yt; the information of ht acts on the input at the next moment. This structure simply imitates the memory function of the human brain. Figure 3 shows Its topology diagram: There is only one hidden layer equation: Where Wx and Wh are the weights of the input and hidden layers, respectively, and b is the bias. LSTM is a kind of RNN (recursive neural network), which is the most widely used in processing time series data. It controls information by gates. There are three gates: input gate it, forget gate ft, output gate ot, and more Hidden layer ht and memory cell ct. Figure 4 is its topology: The input gate controls the input at a certain moment; the forget gate acts on the memory cell at the previous moment to control how much data flow from the previous moment enters the next moment; the memory cell is composed of the input at the previous moment and this The candidate input at the moment is jointly determined; the output gate acts on the memory cell, determines the hidden layer information at this moment, and sends it to the next layer of neural network. All equations are as follows: Where W represents their respective weights, b represents their respective biases, and σ is the logisTIc sigmoid function: Design FPGA module The FPGA used in the study is Xilinx's Zedboard Zynq ZC7020 board. Figure 5 is an overview of it LSTM mainly performs matrix multiplication and calculation of nonlinear functions (tanh, sigmoid), therefore, Q8.8 fixed-point is selected. The matrix multiplication is performed by the MAC unit (MulTIply Accumulate), and there are two data streams: vector and weight matrix stream, as shown in Figure 6(a). The MAC will be reset after one iteration to prevent the previous data from being mixed into the data at the next moment. The non-linear function calculation is performed after the data of the two MAC units are added. At the same time, a rescale module is used to convert 32-bit data into 16-bit data. The scalar calculation module is to calculate ct and ht, which are finally passed into the calculation at the next moment. As shown in Figure 6(b). The whole model one shares three modules shown in Figure 6(a) and one Figure 6(b), as shown in Figure 6(c). The inflow and outflow of data is controlled by DMA (Direct Memory Access) serial port. Since the DMA serial port is independent, a clock module is also needed to control its timing. The clock module is mainly composed of a buffer memory and temporarily stores some data until the data arrives. When the last port data flows into the clock module, it starts to transmit data, which ensures that the input and the weight matrix are related at the same time. Therefore, the operation of the LSTM model is divided into three stages: By training the LSTM network on different platforms, we have obtained a comparison of different models. Table 1 shows the parameters of the platform. The running results are shown in Figure 7. It can be found that even at a clock frequency of 142MHz, the running time under the FPGA platform is much shorter than other platforms, and the parallel processing of eight LSTM memory cells is 16 times faster than Exynos5422. Times the result. Deep learning uses a deep neural network (DeepNeural Networks, DNN) model that contains multiple hidden layers. The inherent parallelism of DNN makes GPUs and FPGAs with large-scale parallel architectures become mainstream hardware platforms for accelerating deep learning. Its outstanding advantage is the ability to customize computing and storage structures according to the characteristics of the application to achieve the hardware structure and deep learning algorithms. Optimal matching to obtain a higher performance-to-power ratio; and the flexible reconstruction function of FPGA also facilitates the fine-tuning and optimization of the algorithm, which can greatly shorten the development cycle. There is no doubt that FPGAs are very promising in the future of deep learning.
The TPU materials type raw cable jacket can guarantee longer lifetime and quality. Coiled cable can be used to carry electrical currents as well as data and signal for telecommunications applications. This versatility makes coil cords ideal for use in environments that are often too rough for non-coiled cable.
It has the ability to extend beyond the natural length at rest, which can be a real space-saving feature. These cords are flexible beyond simple extending and retracting in that they can also be pulled, bent, and twisted without experiencing the metal fatigue of a straight cable.
Flex Coiled Cable Assembly, coiled cable harness, flex coiled wiring cable,High Quality Electrical Wire Harness,light-duty coiled cables ETOP WIREHARNESS LIMITED , https://www.wireharness-assembling.com